Create an incremental artifact when you need to apply changes to a subset of files in an artifact, where the size of the original artifact is much larger.
Create new artifact versions from scratch
You can create a new artifact version in two ways: from a single run and from distributed runs. The following list defines each method:- Single run: A single run provides all the data for a new version. This is the most common case and is best suited when the run fully recreates the needed data. For example, to output saved models or model predictions in a table for analysis.
- Distributed runs: A set of runs collectively provides all the data for a new version. This is best suited for distributed jobs which have multiple runs that generate data, often in parallel. For example, to evaluate a model in a distributed manner and output the predictions.
v0 alias if you pass a name to the wandb.Artifact API that doesn’t exist in your project. W&B checksums the contents when you log again to the same artifact. If the artifact changed, W&B saves a new version v1.
W&B retrieves an existing artifact if you pass a name and artifact type to the wandb.Artifact API that matches an existing artifact in your project. The retrieved artifact already has at least one version (v0 or later).
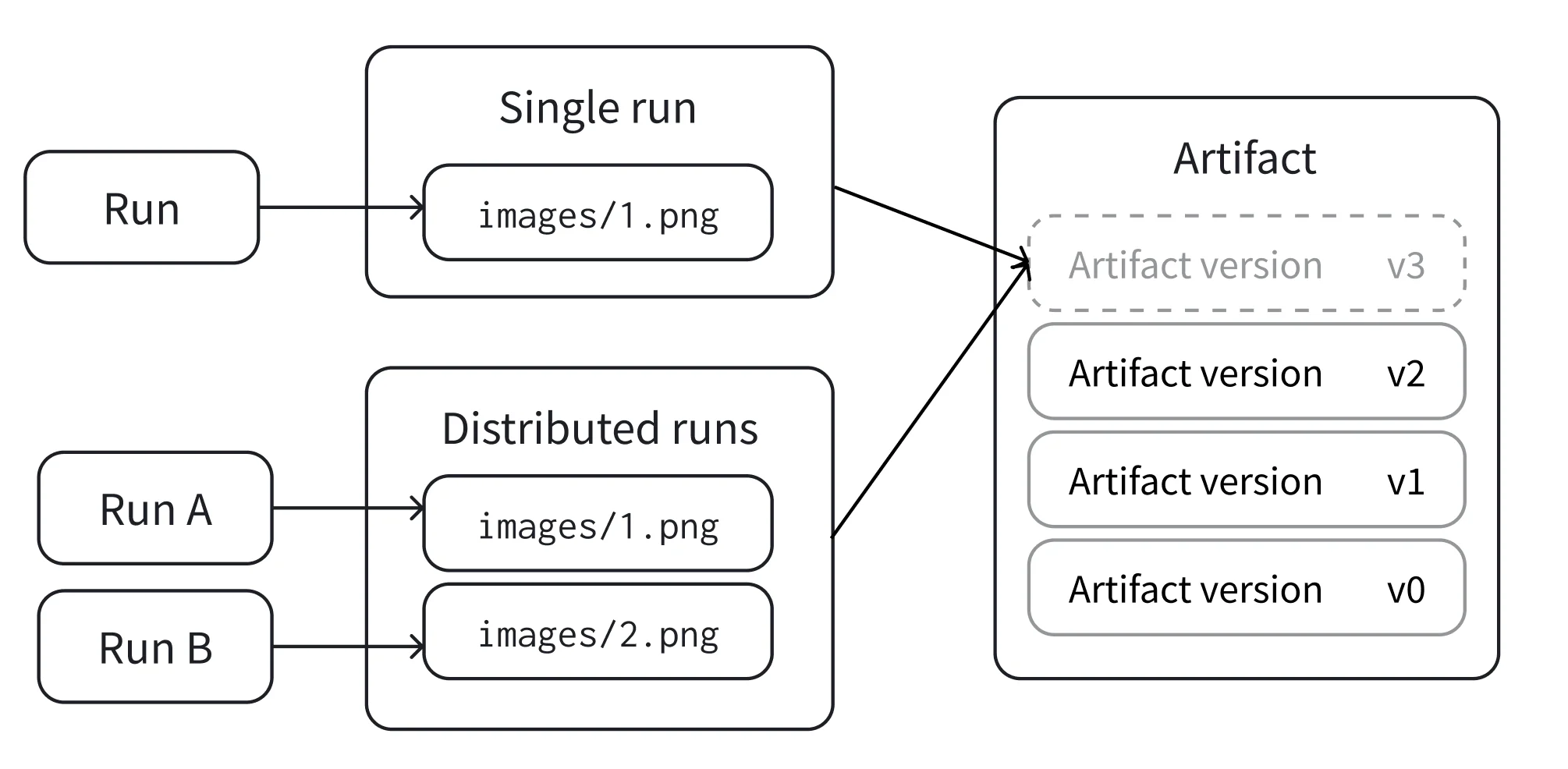
Single run
Log a new version of an artifact with a single run that produces all the files in the artifact. This case occurs when a single run produces all the files in the artifact. You can create a new artifact version either as part of an active W&B run (so the artifact is tracked as that run’s output) or outside of a run (when you want to log artifacts independently of experiment tracking). Based on your use case, select one of the following tabs to create a new artifact version inside or outside of a run:- Inside a run
- Outside of a run
Create an artifact version within a W&B run:
- Create a run with
wandb.init(). - Create a new artifact or retrieve an existing one with
wandb.Artifact. - Add files to the artifact with
.add_file. - Log the artifact to the run with
.log_artifact.
Distributed runs
Allow a collection of runs to collaborate on a version before they commit it. This is in contrast to single-run mode described previously, where one run provides all the data for a new version. Use distributed runs when no single run has access to all the files that belong in the artifact (for example, when several parallel jobs each produce a portion of the output).- Each run in the collection needs the same unique ID (called
distributed_id) to collaborate on the same version. By default, if present, W&B uses the run’sgroupas set bywandb.init(group=GROUP)as thedistributed_id. - A final run must “commit” the version, permanently locking its state.
- Use
upsert_artifactto add to the collaborative artifact andfinish_artifactto finalize the commit.
distributed_id to contribute to a single artifact version and how a final run commits it. Different runs (labeled as Run 1, Run 2, and Run 3 in the following examples) add a different image file to the same artifact with upsert_artifact.
Run 1:
distributed_id. Run 3 must run after Run 1 and Run 2 complete. The run that calls wandb.Run.finish_artifact() can include files in the artifact, but doesn’t need to.
Create a new artifact version from an existing version
Add, modify, or remove a subset of files from a previous artifact version without the need to re-index the files that didn’t change. Adding, modifying, or removing a subset of files from a previous artifact version creates a new artifact version known as an incremental artifact.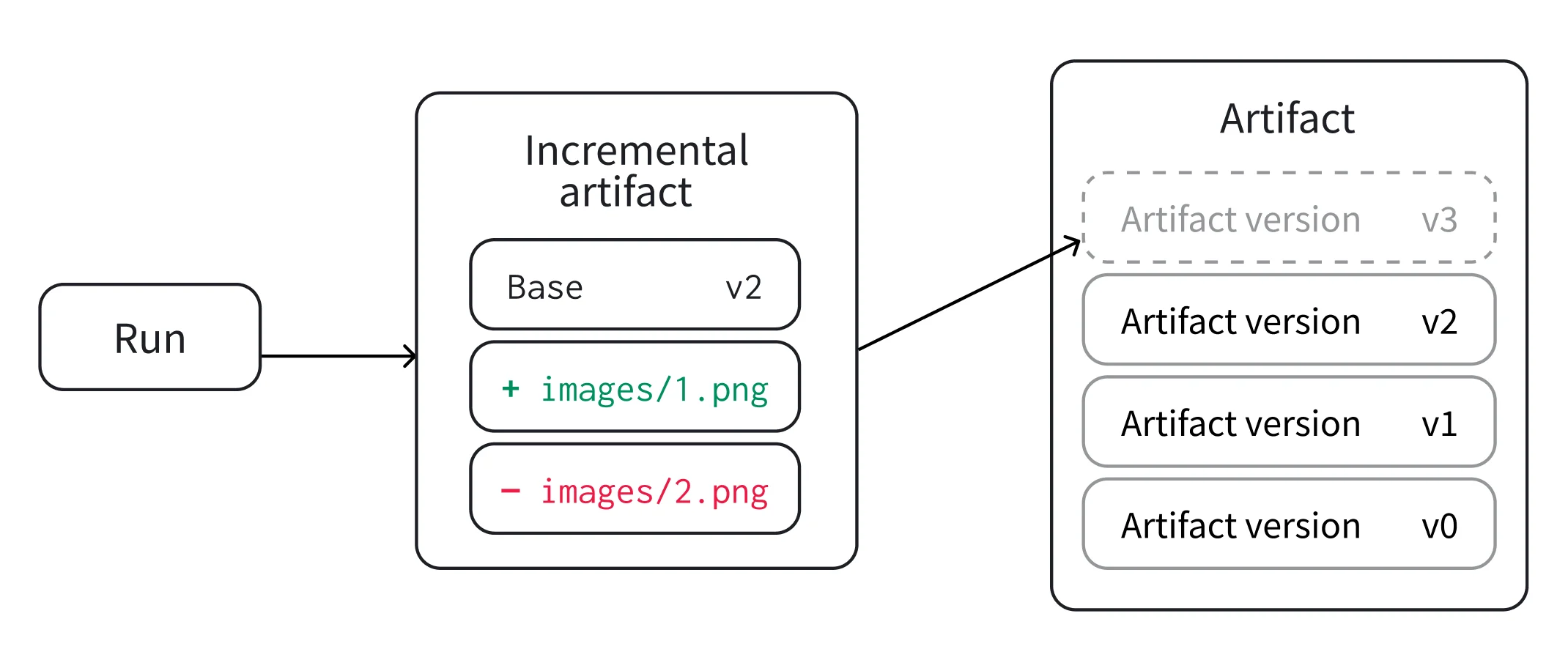
- Add: You periodically add a new subset of files to a dataset after you collect a new batch.
- Remove: You discovered several duplicate files and want to remove them from your artifact.
- Update: You corrected annotations for a subset of files and want to replace the old files with the correct ones.
You can create an incremental artifact within a single run or with a set of runs (distributed mode).
- Obtain the artifact version you want to incrementally change:
- Inside a run
- Outside of a run
- Create a draft with:
- Perform any incremental changes you want to see in the next version. You can add, remove, or modify an existing entry.
- Add
- Remove
- Modify
Add a file to an existing artifact version with the
add_file method:You can also add multiple files by adding a directory with the
add_dir method.- Log or save your changes to commit the draft as a new artifact version. The following tabs show you how to save your changes inside and outside of a W&B run. Select the tab that is appropriate for your use case:
- Inside a run
- Outside of a run
- Inside a run
- Outside of a run